
Apache Lucene – korak do Google-a (3. deo)
Autor: Dejan Čugalj
Mogućnosti Lucene biblioteke su ogromne, a naš cilj je desktop aplikacija koja pretražuje PDF datoteke na lokalnom tvrdom disku i naravno, što bolje upoznavanje sa istom. Pretraga će ići „duboko”, počevši od metapodataka, poput naziva autora, naslova, broja stranica pa sve do samog teksta unutar PDF datoteke.![]()
Podsećamo, da bi cilj bio izvodljiv, potrebno je preduzeti nekoliko koraka pre nego što PDF datoteka bude spremna za Lucene i za njeno indeksiranje.
Da bismo stvorili jasniju sliku projekta, predstavićemo ukratko studiju slučaja (engl. Case studies) kojom ćemo se voditi do kraja serijala, a samim tim i do kraja samog projekta.
Studija slučaja
- Desktop aplikacija za pretragu PDF datoteka na lokalnom tvrdom disku
1. Zbog razumljivosti kôda i izbegavanja komplikovanih delova, pretpostavićemo da se sve PDF datoteke nalaze u jednoj fascikli na lokalnom tvrdom disku i nazvaćemo tu fasciklu „Biblioteka”, za sada.
- Izbegavanja komplikovanijih delova kôda su neophodna zbog programerski manje iskusnih čitaoca LiBRE! časopisa. Pokušaćemo da celu aplikaciju napišemo iz razdvojenih i nezavisnih modula. (Moduli u našem slučaju bi trebalo da su ekvivalentni programskim paketima u Java programskom jeziku). Module ćemo na kraju sinhronizovati u celinu, tako da će svi potrebni koraci do krajnjeg indeksiranja biti, takoreći, programčići sami za sebe, potpuno funkcionalni u pogledu svog postojanja, nezavisni od celine (prim. aut).
- Modularna Java aplikacija je takođe korisna jer njen sam izlaz ne mora da bude desktop aplikacija koju mi trenutno implementiramo, već može da bude JavaEE (WEB), Android, neko će reći to je samo OSGi (OSGi framework, http://www.osgi.org/), ali o tome ćemo nekom drugom prilikom. To su neke od najvećih prednosti Java pisanih aplikacija.
2. Priprema PDF datoteka za Lucene podrazumeva ekstrakciju svih neophodnih podataka, počevši sa metapodacima pa sve do samog teksta koji se nalazi u datoteci.
- Ovo je deo u kojem koristimo TIKA biblioteku koju smo ukratko spomenuli u prošlom broju. Obećali smo da ćemo se bolje upoznati sa njom u ovom, ali zbog ograničenog prostora i obimnosti same teme, ipak ostavljamo za sledeći broj.
3. Implementacija i upotreba Lucene biblioteke.
- Posle, nadamo se, uspešne ekstrakcije podataka u TXT format, potrebnih za indeksiranje, prelazi se u prosleđivanje istih ekstraktovanih podataka Lucene biblioteci. Osvrt na sve neophodne korake i suštine koja će nas odvesti do cilja, deo je koji će verovatno biti najzanimljiviji našim čitaocima.
4. Prikaz rezultata za zadati upit (Query) koji je korisnik prosledio aplikaciji.
- Ovaj deo je samo ulepšavanje prikaza rezultata dobijenih za korisnikov upit ili kraće rečeno, prikaz preko grafičkog interfejsa. Iako ovo izgleda banalno, ovo je jedan od najbitnijih delova, jer logično, ako korisnik nema dobar prikaz rezultata, ne vredi nam ni najbolje napisan programski kôd.
Detaljniji prikaz svih modula se vidi na dijagramu sa slike.
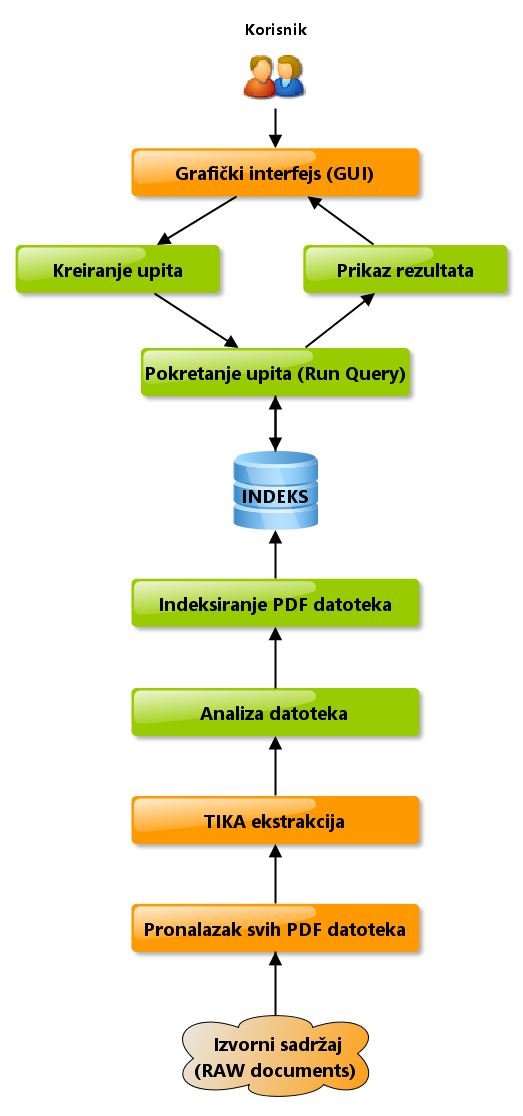
Ovako bi izgledao naš početni Case Studies. Tok realizacije modula će ići odozdo naviše. Elementi obojeni narandžastom bojom su oni koje ćemo mi morati da implementiramo, dok elementi zelene boje su oni koje nam Lucene daje. Pokušaćemo da objasnimo i opišemo što bolje svaki element studije slučaja, praćen dijagramom sa slike. Izmene i odstupanja su tokom implementacije neminovne, skoro neizbežne. Nadam se da će vam ova „vožnja” prijati makar samo deo onog koliko prija i meni pišući ove tekstove (prim. aut).
Ceo kôd biće napisan u Java programskom jeziku, a rezultate onih modula koje smo spomenuli ranije, ćemo prikazati, za sada, u konzolnom ispisu (Integrated Development Environment – IDE) okruženja vama omiljenom ili onom koji vama najviše odgovara.
Moj omiljeni IDE je Eclipse (koristan link http://www.eclipse.org), a ponekad koristim i NetBeans (koristan link https://netbeans.org). Moja malenkost u ovom projektu će koristiti Eclipse IDE (prim. aut).
Implementacija studije slučaja
1. RAW datoteke

U tački jedan studije slučaja smo naveli da pretpostavljamo i da je potrebno da sve naše PDF datoteke budu u fascikli koju smo načelno nazvali „Biblioteka”, pa bi u ovom momentu trebalo da napravimo fasciklu sa prethodno navedenim imenom i da je sačuvamo na lako dostupnoj lokaciji vašeg tvrdog diska. Za početak kopirajte u tu fasciklu nekoliko PDF-ova koje nađete, a bilo bi poželjno da nisu preveliki, što znači da bi optimalna veličina trebalo da bude oko 1-2 [MB] (npr. sva izdanja LiBRE! časopisa).
2. Pronalazak svih PDF datoteka u fasciklama

U analizu ovog dela kôda se nećemo upuštati jer trenutno nije tema koja nas zanima. Ukratko, konstruktoru klase RawDokument-a prosleđujemo kao parametar putanju do fascikle gde se nalaze PDF datoteke ili samo naziv jedne datoteke koju učitavamo u neku strukturu podataka, koja će nam omogućiti dalji rad sa podacima u njoj. Struktura podataka koju smo odabrali je ArrayList, ali to je samo naš izbor, razlog je onaj koji se spominje u tački jedan studije slučaja, vaš izbor može da bude bilo koji.
[code]
package org.lugons.libre.lucene.rawfajlovi;
import java.io.*;
import java.util.ArrayList;
public class RawDokumenta {
private ArrayList
public RawDokumenta(String putanja) {
pronadjiFajlove(new File(putanja));
}
public ArrayList
return listaFajlova;
}
private void pronadjiFajlove(File file) {
// Ako fascikla ili datoteka ne postoje
if (!file.exists()) {
System.out.println(file + " ne postoji.");
}
// Ako je fascikla – Recursion
if (file.isDirectory()) {
for (File f : file.listFiles()) {
pronadjiFajlove(f);
}
} else {
String imeFajla = file.getName().toLowerCase();
// ===================================================
// Samo pronađi PDF datoteke
// ===================================================
if (imeFajla.endsWith(".pdf")) {
// System.out.println("Nađen fajl: " + file.getName());
getListaFajlova().add(file);
} else {
// System.out.println("Preskočeno " + filename);
}
}
}
public static void main(String[] args) throws IOException {
System.out.println("Unesite putanju do direktorijuma ili fajla: (npr. /tmp/Biblioteka ili c:\\temp\\Biblioteka)");
BufferedReader br = new BufferedReader(new InputStreamReader(System.in));
String unosKorisnika = br.readLine();
RawDokumenta raw = new RawDokumenta(unosKorisnika);
System.out.println("Pronađeni fajlovi: " + raw.getListaFajlova());
}
}
[/code]
Poziv iz neke druge klase:
[code]
public static void main(String[] args) {
RawDokumenta raw = new RawDokumenta("/tmp/Biblioteka");
for(File file : raw.getListaFajlova()){
System.out.println("Nađen fajl: " + file.getName());
}
}[/code]
Klasa RawDokument-a nema veze sa Lucene, trenutno, ali će nam koristiti prilikom pretrage PDF datoteka i ako pokrenete ovaj modul, ispisaće vam u konzoli IDE okruženja koji koristite, sve PDF datoteke u fascikli koju ste prosledili kao argument konstruktoru.
Svim čitaocima našeg časopisa koji nisu skloni programiranju – kraj serijala i sama aplikacija koju ćemo napisati, doneće kao rezultate pretragu svih preuzetih izdanja LiBRE! časopisa i detaljno uputstvo kako to da urade.
Ovim završavamo prva dva modula i naravno, ako ne budemo zadovoljni njima tj. klasom RawDokument-a, moraćemo da je izmenimo. U sledećem broju LiBRE! časopisa predstavićemo paketnu strukturu projekta i TIKA biblioteku kao premijeru trećeg modula pod nazivom TIKA ekstrakcija.