

Apache Lucene – korak do Google-a (5. deo)
Autor: Dejan Čugalj
Posle pauze koja je potrajala, vraćamo se implementaciji modula koji su nam neophodni za ostvarenje krajnjeg cilja koji smo zadali sebi još u 12. broju LiBRE! časopisa.
Poslednji članak o ovoj temi objavljen je u 15. broju, i zbog toga ćemo se podsetiti šta je sve urađeno do sada. U 12. broju smo predstavili neke uporedne podatke ljudske potrebe za pretraživačima u informacionim tehnologijama i ukratko smo spomenuli Lucene biblioteku. Broj 13. smo iskoristili za detaljnije upoznavanje sa istom, dok smo u broju 14. potpuno ušli u priču i predstavili studiju slučaja predstojećeg projekta. U 15. broju LiBRE! časopisa, tj. u četvrtom nastavku serije članaka „Lucene – korak do Google-a”, počinjemo sa implementacijom projektnih modula Lucene projekta. U tom izdanju smo implementirali prva dva modula: „Pronalazak svih PDF datoteka” i „Tika ekstrakcija”. Takođe, ovaj izuzetan Apache Tika framework našao je svoje mesto u zasebnom članku i približio nam svoje mogućnosti.
S obzirom na količinu kôda koji će biti napisan, odlučili smo se za GitHub javni repozitorijum (Koristan link: https://github.com/libreoss/lucene-moduli) u koji je postavljen celokupan kôd, dok one najbitnije delove objavljujemo u časopisu. Nekako, kada sve saberemo i oduzmemo, to je ono što bi predstavilo kratku rekapitulaciju serijala „Lucene – korak do Google-a”.
Peti deo serijala nam donosi nastavak implementacije modula i to su: „Analiza dokumenata”, „Indeksiranje PDF datoteka” i „Indeks (pregled Lucene strukture datoteka)”. Ovo je dobar momenat da podsetimo da svi moduli iz studije slučaja obojeni zelenom bojom jesu tačnije oni delovi gde nam Lucene pruža svoje usluge i dovoljno je samo biti upoznat sa njenim API-jem (engl. Application Programming Interface) da bi se mogla i koristiti. Upravo taj API (http://bit.ly/SBcNKf) i dokumentacija dostupni su na adresi: http://lucene.apache.org/core/4_8_0/index.html (verzija aktuelna u toku pisanja ovog članka je 4.8.0).
Pre nego što počnemo, potrebno je dodati Lucene biblioteke u Eclipse IDE okruženje, koje su dostupne za preuzimanje sa zvaničnog sajta na adresi: http://lucene.apache.org/core/. Dodavanje biblioteka u projekat Eclipse IDE okruženja detaljno je objašnjeno na adresi: http://bit.ly/1qfFRpb
4. Analiza datoteka

U prvom delu serijala, ako ste pažljivo čitali, dotakli smo se tokenizacije i šta bi ona ukratko trebalo da predstavlja (12. broj LiBRE! časopisa). Upravo je ovo deo gde ona dolazi do značaja. Pretraživači ne indeksiraju tekst direktno, već se sadržaj, kandidat za indeksiranje, rastavlja na manje delove (Atomic part), koji se nazivaju token-i. Upravo se ovaj proces odvija u ovom modulu. Kako se ovo odvija implicitno, oko ovog modula u ovom momentu ne moramo previše da brinemo, ali ako bismo se udubili u problematiku, videli bismo da je od velikog značaja i da je jedan od ozbiljnijih problema. Ukratko, prilikom ovog procesa rešavaju se krucijalna pitanja kao što su: da li je potrebno obraćati pažnju na smisao reči (problem sinonima), da li je potrebno prilikom pretraživanja obratiti pažnju na semantičku stranu prirode reči kao što su laptop i računar, da li je potrebno uzimati u obzir infinitiv? Problemi i pitanja se mogu dovesti do filozofsko-filološkog nivoa, tako da bismo ovu temu ostavili za neke druge, filološke nauke. Ono što je bitno za nas, jeste to da Lucene daje niz alata, sa kojima makar iole možemo da se približimo nekim realnim rezultatima. I konačno, dolazimo do najbitnijeg dela i srži ovog serijala, a to je „indeksiranje”.
5. Indeksiranje

Do sada smo, možda i prečesto, spominjali ovu famoznu reč „indeksiranje”, tako da ovo zauzima centralni i najbitniji deo celog serijala. Kako bi hteli da ovaj deo bude respektivno, koliko je to moguće, približan kvalitetu uloženog truda u razvijanju Lucene, ovde stajemo i primer dajemo malim „školskim primerom” implementacije Lucene indeksiranja napisanim u Java programskom jeziku. S obzirom da je ovo centralni (core) deo serijala, respektivno zaslužuje i mesto u njemu, tako da ćemo ga detaljno predstaviti u sledećem nastavku.
[code]
import java.io.File;
import org.apache.lucene.analysis.Analyzer;
import org.apache.lucene.analysis.standard.StandardAnalyzer;
import org.apache.lucene.document.Document;
import org.apache.lucene.document.Field;
import org.apache.lucene.document.StringField;
import org.apache.lucene.index.IndexWriter;
import org.apache.lucene.index.IndexWriterConfig;
import org.apache.lucene.store.Directory;
import org.apache.lucene.store.FSDirectory;
import org.apache.lucene.util.Version;
/** * */
public class LuceneIndexExample {
public static void main(String args[]) throws Exception {
String text = "Ovo je tekst indeksiran sa Lucene";
String indexDir = System.getProperty("user.dir")
+ System.getProperty("file.separator") + "index";
System.out.println(indexDir);
Directory dir = FSDirectory.open(new File(indexDir));
Analyzer analyzer = new StandardAnalyzer(Version.LUCENE_48);
IndexWriterConfig iwc = new IndexWriterConfig(Version.LUCENE_48, analyzer);
IndexWriter writer = new IndexWriter(dir, iwc);
Document document = new Document();
Field pathField = new StringField("ime_polja", text, Field.Store.YES);
document.add(pathField);
writer.addDocument(document);
writer.close();
}
}
[/code]
6. Indeks (pregled Lucene strukture datoteka)
 Osnovni i fundamentalan koncept Lucene jesu: indeks (index), dokument (document), polje (field) i pojam (term). Kada bismo to „sklopili”, dobili bismo strukturu da indeks sadrži sekvence dokumenta. Dokument je sekvenca polja, polje je imenovana sekvenca pojma, dok je pojam sekvenca bajtova.
Osnovni i fundamentalan koncept Lucene jesu: indeks (index), dokument (document), polje (field) i pojam (term). Kada bismo to „sklopili”, dobili bismo strukturu da indeks sadrži sekvence dokumenta. Dokument je sekvenca polja, polje je imenovana sekvenca pojma, dok je pojam sekvenca bajtova.
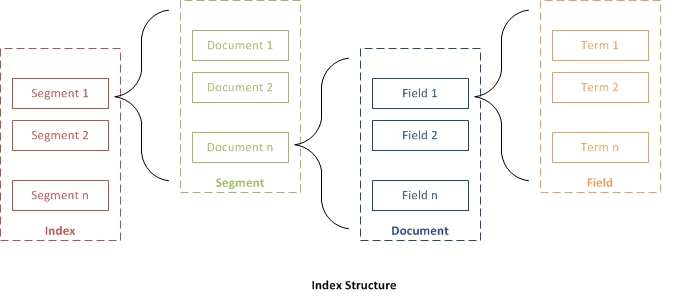
Uglavnom, cela magija se odvija pod „Lucene haubom” i, ukoliko bismo želeli da uđemo dublje u tematiku, sigurno bi nam ponestalo prostora. Ovo je sasvim dovoljno za sticanje slike i saznanja da posle indeksiranja, Lucene pravi svoju strukturu fajlova koja se posle koristi za pretragu.
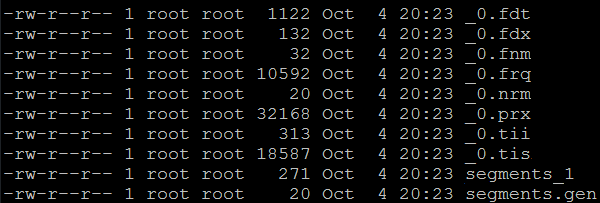
Vidimo se u sledećem broju sa našim „Lucene indeksima”.
Korisni linkovi:
- Zvanični sajt:http://bit.ly/LdDxwN
- Izvorni kôd: http://bit.ly/1pIFmQo
- Sistemski zahtevi:http://bit.ly/1kN0bXP