
Apache Lucene – корак до Google-a (3. део)
Аутор: Дејан Чугаљ
Могућности Lucene библиотеке су огромне, а наш циљ је desktop апликација која претражује PDF датотеке на локалном тврдом диску и наравно, што боље упознавање са истом. Претрага ће ићи „дубоко”, почевши од метаподатака, попут назива аутора, наслова, броја страница па све до самог текста унутар PDF датотеке.![]()
Подсећамо, да би циљ био изводљив, потребно је предузети неколико корака пре него што PDF датотека буде спремна за Lucene и за њено индексирање.
Да бисмо створили јаснију слику пројекта, представићемо укратко студију случаја (енгл. Case studies) којом ћемо се водити до краја серијала, а самим тим и до краја самог пројекта.
Студија случаја
-
Desktop апликација за претрагу PDF датотека на локалном тврдом диску
1. Због разумљивости кôда и избегавања компликованих делова, претпоставићемо да се све PDF датотеке налазе у једној фасцикли на локалном тврдом диску и назваћемо ту фасциклу „Biblioteka”, за сада.
-
Избегавања компликованијих делова кôда су неопходна због програмерски мање искусних читаоца ЛиБРЕ! часописа. Покушаћемо да целу апликацију напишемо из раздвојених и независних модула. (Модули у нашем случају би требало да су еквивалентни програмским пакетима у Java програмском језику). Модуле ћемо на крају синхронизовати у целину, тако да ће сви потребни кораци до крајњег индексирања бити, такорећи, програмчићи сами за себе, потпуно функционални у погледу свог постојања, независни од целине (прим. аут).
-
Модуларна Java апликација је такође корисна јер њен сам излаз не мора да буде desktop апликација коју ми тренутно имплементирамо, већ може да буде JavaEE (WEB), Android, неко ће рећи то је само OSGi (OSGi framework, http://www.osgi.org/), али о томе ћемо неком другом приликом. То су неке од највећих предности Java писаних апликација.
2. Припрема PDF датотека за Lucene подразумева екстракцију свих неопходних података, почевши са метаподацима па све до самог текста који се налази у датотеци.
-
Ово је део у којем користимо TIKA библиотеку коју смо укратко споменули у прошлом броју. Обећали смо да ћемо се боље упознати са њом у овом, али због ограниченог простора и обимности саме теме, ипак остављамо за следећи број.
3. Имплементација и употреба Lucene библиотеке.
-
После, надамо се, успешне екстракције података у TXT формат, потребних за индексирање, прелази се у прослеђивање истих екстрактованих података Lucene библиотеци. Осврт на све неопходне кораке и суштине која ће нас одвести до циља, део је који ће вероватно бити најзанимљивији нашим читаоцима.
4. Приказ резултата за задати упит (Query) који је корисник проследио апликацији.
-
Овај део је само улепшавање приказа резултата добијених за корисников упит или краће речено, приказ преко графичког интерфејса. Иако ово изгледа банално, ово је један од најбитнијих делова, јер логично, ако корисник нема добар приказ резултата, не вреди нам ни најбоље написан програмски кôд.
Детаљнији приказ свих модула се види на дијаграму са слике.
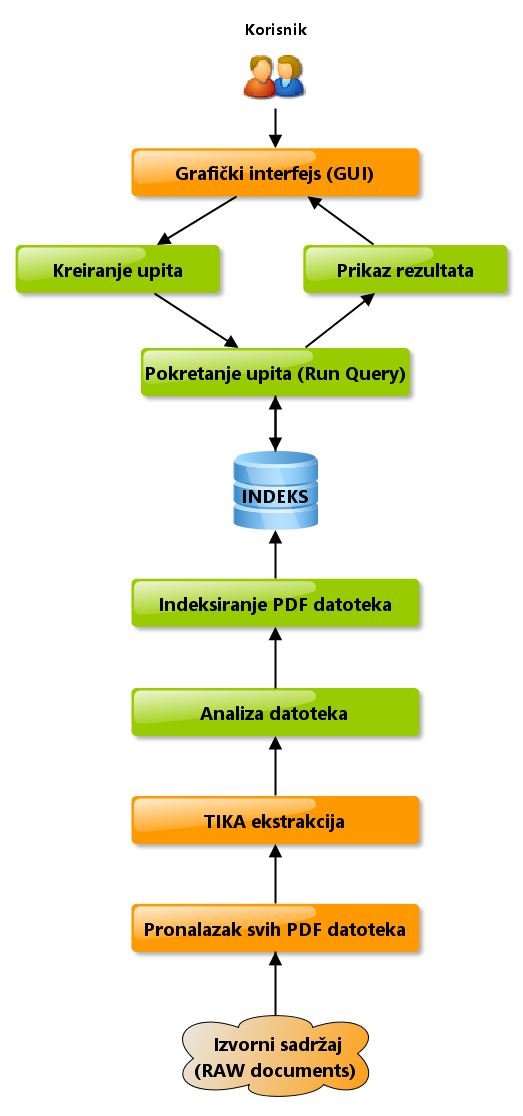
Овако би изгледао наш почетни Case Studies. Ток реализације модула ће ићи одоздо навише. Елементи обојени наранџастом бојом су они које ћемо ми морати да имплементирамо, док елементи зелене боје су они које нам Lucene даје. Покушаћемо да објаснимо и опишемо што боље сваки елемент студије случаја, праћен дијаграмом са слике. Измене и одступања су током имплементације неминовне, скоро неизбежне. Надам се да ће вам ова „вожња” пријати макар само део оног колико прија и мени пишући ове текстове (прим. аут).
Цео кôд биће написан у Java програмском језику, а резултате оних модула које смо споменули раније, ћемо приказати, за сада, у конзолном испису (Integrated Development Environment – IDE) окружења вама омиљеном или оном који вама највише одговара.
Мој омиљени IDE је Eclipse (користан линк http://www.eclipse.org), а понекад користим и NetBeans (користан линк https://netbeans.org). Моја маленкост у овом пројекту ће користити Eclipse IDE (прим. аут).
Имплементација студије случаја
1. RAW датотеке

У тачки један студије случаја смо навели да претпостављамо и да је потребно да све наше PDF датотеке буду у фасцикли коју смо начелно назвали „Biblioteka”, па би у овом моменту требало да направимо фасциклу са претходно наведеним именом и да је сачувамо на лако доступној локацији вашег тврдог диска. За почетак копирајте у ту фасциклу неколико PDF-ова које нађете, а било би пожељно да нису превелики, што значи да би оптимална величина требало да буде око 1-2 [MB] (нпр. сва издања ЛиБРЕ! часописа).
2. Проналазак свих PDF датотека у фасциклама

У анализу овог дела кôда се нећемо упуштати јер тренутно није тема која нас занима. Укратко, конструктору класе RawDokument-а прослеђујемо као параметар путању до фасцикле где се налазе PDF датотеке или само назив једне датотеке коју учитавамо у неку структуру података, која ће нам омогућити даљи рад са подацима у њој. Структура података коју смо одабрали је ArrayList, али то је само наш избор, разлог је онај који се спомиње у тачки један студије случаја, ваш избор може да буде било који.
[code]
package org.lugons.libre.lucene.rawfajlovi;
import java.io.*;
import java.util.ArrayList;
public class RawDokumenta {
private ArrayList<File> listaFajlova = new ArrayList<File>();
public RawDokumenta(String putanja) {
pronadjiFajlove(new File(putanja));
}
public ArrayList<File> getListaFajlova() {
return listaFajlova;
}
private void pronadjiFajlove(File file) {
// Ако фасцикла или датотека не постоје
if (!file.exists()) {
System.out.println(file + " ne postoji.");
}
// Ако је фасцикла – Recursion
if (file.isDirectory()) {
for (File f : file.listFiles()) {
pronadjiFajlove(f);
}
} else {
String imeFajla = file.getName().toLowerCase();
// ===================================================
// Само пронађи PDF датотеке
// ===================================================
if (imeFajla.endsWith(".pdf")) {
// System.out.println("Nađen fajl: " + file.getName());
getListaFajlova().add(file);
} else {
// System.out.println("Preskočeno " + filename);
}
}
}
public static void main(String[] args) throws IOException {
System.out.println("Unesite putanju do direktorijuma ili fajla: (npr. /tmp/Biblioteka ili c:\\temp\\Biblioteka)");
BufferedReader br = new BufferedReader(new InputStreamReader(System.in));
String unosKorisnika = br.readLine();
RawDokumenta raw = new RawDokumenta(unosKorisnika);
System.out.println("Pronađeni fajlovi: " + raw.getListaFajlova());
}
}
[/code]
Позив из неке друге класе:
[code]
public static void main(String[] args) {
RawDokumenta raw = new RawDokumenta("/tmp/Biblioteka");
for(File file : raw.getListaFajlova()){
System.out.println("Nađen fajl: " + file.getName());
}
}[/code]
Класа RawDokument-а нема везе са Lucene, тренутно, али ће нам користити приликом претраге PDF датотека и ако покренете овај модул, исписаће вам у конзоли IDE окружења који користите, све PDF датотеке у фасцикли коју сте проследили као аргумент конструктору.
Свим читаоцима нашег часописа који нису склони програмирању – крај серијала и сама апликација коју ћемо написати, донеће као резултате претрагу свих преузетих издања ЛиБРЕ! часописа и детаљно упутство како то да ураде.
Овим завршавамо прва два модула и наравно, ако не будемо задовољни њима тј. класом RawDokument-а, мораћемо да је изменимо. У следећем броју ЛиБРЕ! часописа представићемо пакетну структуру пројекта и TIKA библиотеку као премијеру трећег модула под називом TIKA екстракција.