
Apache Lucene – korak do Google-a (4. deo)
Autor: Dejan Čugalj
Podsetnik
U broju 14. LiBRE! časopisa smo predstavili studiju slučaja aplikacije koju razvijamo i preko koje ćemo se upoznati detaljno sa Lucene bibliotekom. Programerskim žargonom rečeno, videli smo pregled aplikacije i njenih delova sa visokog nivoa (engl. High level preview). Značenje „visok nivo” u ovom kontekstu je, u suštini, prikaz toka razvoja bez upuštanja u previše detalja.![]()
U dijagramu smo videli neophodne korake (u daljem tekstu moduli) koje moramo da implementiramo – neke sami (moduli obojeni narandžastom bojom), a neke koje će nam pri implementaciji pomoći Lucene (moduli obojeni zelenom bojom). Takođe smo implementirali prva dva modula: „RAW datoteke” i „Pronalazak svih PDF dokumenata”. Pre prelaska na implementaciju Lucene nedostaje nam samo još da implementiramo ekstrakciju metapodataka i sadržaja, da vidimo kako izgleda paketna struktura projekta i, naravno, izrada korisničkog grafičkog interfejsa (Graphical User Interface – GUI) aplikacije, koju ostavljamo za kraj serijala.
3. TIKA ekstrakcija

Premijera trećeg modula koji implementiramo je TIKA biblioteka, koja će nam omogućiti ekstrakciju teksta iz PDF dokumenata – u našem slučaju LiBRE! časopisa, u tekstualni format (TXT) koji Lucene može da obradi, tj. da indeksira.
TIKA biblioteka je sama po sebi „malo teška”, jer je njena veličina negde oko 27 [MB] i, sagledavajući korake iz studije slučaja, možemo primetiti da nam ona i nije preko potrebna iz prostog razloga što se baziramo samo na PDF datoteke. Obzirom da se TIKA za ekstrakciju PDF datoteka oslanja na projekat koji je pod Apache „kišobranom”, pod nazivom PDFBox (korisna adresa: http://pdfbox.apache.org) i koji je pod licencom Apache v2.0, mogli bismo da koristimo samo spomenutu biblioteku. Međutim, izbor koji smo doneli je ipak TIKA biblioteka, zbog proširivosti same aplikacije; šta ako nam zatreba ili se odlučimo u nekom momentu da aplikaciji prosledimo datoteku koja nema PDF ekstenziju? To bi izazvalo skoro sigurno izmenu samog izvornog kôda i propratne, bespotrebne komplikacije (prim. aut.).
Prvi korak koji je potrebno da uradimo je preuzimanje TIKA biblioteke sa adrese: http://tika.apache.org/download.html. Verzija koja je aktuelna dok pišemo ovaj članak je 1.4 (objavljena 03.07.2013. godine). Tačan naziv datoteke koju bi trebalo da preuzmemo je „tika-app-1.4.jar”. Ako vas je zainteresovala TIKA, projekat sa izvornim kôdom možete pogledati na GitHub-u (korisna adresa https://github.com/apache/tika).
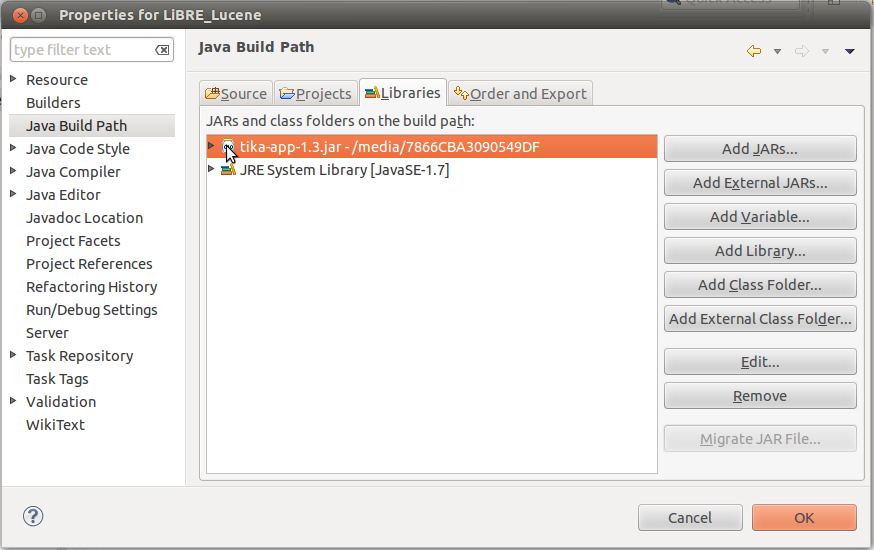
Spomenuli smo u prošlom broju da ćemo za ovaj projekat koristiti programersko okruženje Eclipse, pa nakon preuzimanja gorespomenute datoteke potrebno je istu uvrstiti u Java putanju (Java build path) Eclipse okruženja i spremni smo za implementaciju kôda.
Ili, ako ste se odlučili da koristite MAVEN projekat, dovoljno je da dodate TIKU u vaš „pom.xml” (Project Object Model – POM):
[code]
[/code]
Takođe napominjemo da ste dodavanjem TIKA zavisnosti u vaš projekat obezbedili da sve neophodne biblioteke, koje su potrebne za TIKA parsiranja, budu na pravom mestu u putanji projekta.
Kako LiBRE! časopis ima otvorenu GitHub organizaciju na adresi: https://github.com/libreoss, „nepotrebne” delove kôda nećemo predstavljati u samim člancima, već samo one koji su nam najbitniji za module koje trenutno implementiramo.
Svi delovi kôda i klasa, u toku implementacije modula, koje smo napisali u prošlim, sadašnjim i budućim člancima su dostupni na LiBRE! GitHub-u, u skladištu programskih paketa „lucene-moduli”.
Deo koji je najbitniji za celu klasu „TikaEkstrakcija” je metoda „parsiranjeDokumenata” i kôd koji smo želeli da vam prikažemo u časopisu je samo deo cele klase. Važnost ove metode je suština koja prikazuje TIKA implementaciju ekstrakcije metapodataka i sadržaja prosleđene datoteke.
Kôd cele klase „TikaEkstrakcija” možete pogledati na adresi: http://bit.ly/142BqwP, dok najbitniji deo izdvajamo za vas.
[code]
private String parsiranjeDokumenata(String putanja) throws IOException {
InputStream is = null;
ContentHandler nosacSadrzaja = null;
Metadata metadata;
AutoDetectParser parser;
try {
metadata = new Metadata();
is = new FileInputStream(putanja);
/**
* Maksimalan broj karaktera za upis u InputStream. -1 za MAX
*/
nosacSadrzaja = new BodyContentHandler(-1);
parser = new AutoDetectParser();
parser.parse(is, nosacSadrzaja, metadata, new ParseContext());
processMetaData(metadata);
sviMetapodaci(getMetaData());
//log.info(nosacSadrzaja.toString());
} catch (Exception e) {
e.printStackTrace();
} finally {
if (is != null)
IOUtils.closeQuietly(is);
}
return nosacSadrzaja.toString();
}
[/code]
Detalje TIKA biblioteke smo opisali u članku „Apache TIKA freamework” koji je takođe izašao u ovom broju LiBRE! časopisa, u rubrici „Internet mreže i komunikacije”. Detalje i uputstvo kako pokrenuti ekstrakciju su opisani na adresi http://bit.ly/17CP0ew.
Paketna struktura projekta
Paketna struktura projekata pisanih u Java programskom jeziku je identična hijerarhijskoj strukturi fascikli fajl sistema u operativnom sistemu koji koristite. Svaka fascikla u Java-inom programu se naziva „paket”. Paketi (fascikle) nam omogućavaju da grupišimo klase koje po svojoj funkciji i nameni imaju nešto zajedničko, tako da smo, vodeći se studijom slučaja i dijagramom opisanih u prošlom broju, došli do nekog logičnog zaključka da bi struktura projekta, preliminarno, mogla da izgleda kao na slici.
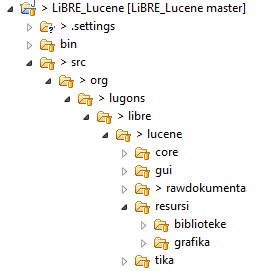
Prva dva modula su u paketu „rawdokumenta”. Treći implementiran modul „Tika ekstrakcija” je u paketu koji smo nazvali „tika”, tako da će izvorni kôd aplikacije imati strukturu koju će biti lakše ispravljati, održavati, itd. Naravno da ovim nismo opisali kako se u Java programiranju konvencionalno koriste paketi, ali to je tema za neki drugi članak.
Iako smo do sada implementirali tri modula, oni nisu u direktnoj vezi sa Lucene, ali su ipak jedan od bitnijih delova aplikacije i uopšteno implementacije Lucene biblioteke. Parsiranje, ekstrakcija, izdvajanje podataka iz raznih struktura podataka, bilo da su binarnog ili nekog drugog formata, nije naivno i treba da se obrati pažnja na mnogo detalja, počevši od proučavanja i upoznavanja standardizacije tipa dokumenta koji parsiramo, do semantičkih detalja vezanih za kontekst samog teksta.
U sledećem broju LiBRE! časopisa ćemo izvršiti implementaciju još dva modula za koje nam Lucene omogućava API (Application Programming Interface – API).