
Apache Lucene – корак до Google-а (4. део)
Аутор: Дејан Чугаљ
Подсетник
У броју 14. ЛиБРЕ! часописа смо представили студију случаја апликације коју развијамо и преко које ћемо се упознати детаљно са Lucene библиотеком. Програмерским жаргоном речено, видели смо преглед апликације и њених делова са високог нивоа (енгл. High level preview). Значење „висок ниво” у овом контексту је, у суштини, приказ тока развоја без упуштања у превише детаља.![]()
У дијаграму смо видели неопходне кораке (у даљем тексту модули) које морамо да имплементирамо – неке сами (модули обојени наранџастом бојом), а неке које ће нам при имплементацији помоћи Lucene (модули обојени зеленом бојом). Такође смо имплементирали прва два модула: „RAW датотеке” и „Проналазак свих PDF докумената”. Пре преласка на имплементацију Lucene недостаје нам само још да имплементирамо екстракцију метаподатака и садржаја, да видимо како изгледа пакетна структура пројекта и, наравно, израда корисничког графичког интерфејса (Graphical User Interface – GUI) апликације, коју остављамо за крај серијала.
3. TIKA екстракција

Премијера трећег модула који имплементирамо је TIKA библиотека, која ће нам омогућити екстракцију текста из PDF докумената – у нашем случају ЛиБРЕ! часописа, у текстуални формат (TXT) који Lucene може да обради, тј. да индексира.
TIKA библиотека је сама по себи „мало тешка”, јер је њена величина негде око 27 [MB] и, сагледавајући кораке из студије случаја, можемо приметити да нам она и није преко потребна из простог разлога што се базирамо само на PDF датотеке. Обзиром да се TIKA за екстракцију PDF датотека ослања на пројекат који је под Apache „кишобраном”, под називом PDFBox (корисна адреса: http://pdfbox.apache.org) и који је под лиценцом Apache v2.0, могли бисмо да користимо само споменуту библиотеку. Међутим, избор који смо донели је ипак TIKA библиотека, због проширивости саме апликације; шта ако нам затреба или се одлучимо у неком моменту да апликацији проследимо датотеку која нема PDF екстензију? То би изазвало скоро сигурно измену самог изворног кôда и пропратне, беспотребне компликације (прим. аут.).
Први корак који је потребно да урадимо је преузимање TIKA библиотеке са адресе: http://tika.apache.org/download.html. Верзија која је актуелна док пишемо овај чланак је 1.4 (објављена 03.07.2013. године). Тачан назив датотеке коју би требало да преузмемо је „tika-app-1.4.jar”. Ако вас је заинтересовала TIKA, пројекат са изворним кôдом можете погледати на GitHub-у (корисна адреса https://github.com/apache/tika).
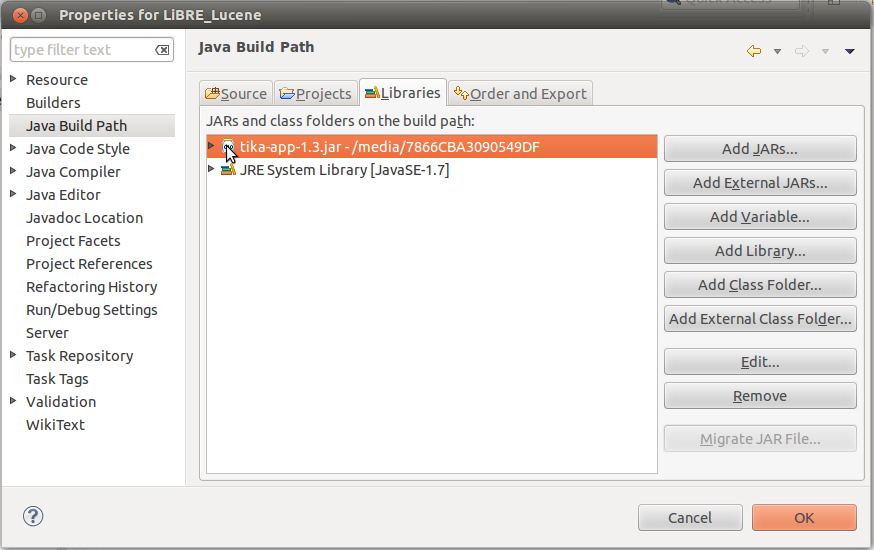
Споменули смо у прошлом броју да ћемо за овај пројекат користити програмерско окружење Eclipse, па након преузимања гореспоменуте датотеке потребно је исту уврстити у Java путању (Java build path) Eclipse окружења и спремни смо за имплементацију кôда.
Или, ако сте се одлучили да користите MAVEN пројекат, довољно је да додате TIKU у ваш „pom.xml” (Project Object Model – POM):
[code]
<dependency>
<groupId>org.apache.tika</groupId>
<artifactId>tika-parsers</artifactId>
<version>1.4</version>
<type>jar</type>
</dependency>
[/code]
Такође напомињемо да сте додавањем TIKA зависности у ваш пројекат обезбедили да све неопходне библиотеке, које су потребне за TIKA парсирања, буду на правом месту у путањи пројекта.
Како ЛиБРЕ! часопис има отворену GitHub организацију на адреси: https://github.com/libreoss, „непотребне” делове кôда нећемо представљати у самим чланцима, већ само оне који су нам најбитнији за модуле које тренутно имплементирамо.
Сви делови кôда и класа, у току имплементације модула, које смо написали у прошлим, садашњим и будућим чланцима су доступни на ЛиБРЕ! GitHub-у, у складишту програмских пакета „lucene-moduli”.
Део који је најбитнији за целу класу „TikaEkstrakcija” је метода „parsiranjeDokumenata” и кôд који смо желели да вам прикажемо у часопису је само део целе класе. Важност ове методе је суштина која приказује TIKA имплементацију екстракције метаподатака и садржаја прослеђене датотеке.
Кôд целе класе „TikaEkstrakcija” можете погледати на адреси: http://bit.ly/142BqwP, док најбитнији део издвајамо за вас.
[code]
private String parsiranjeDokumenata(String putanja) throws IOException {
InputStream is = null;
ContentHandler nosacSadrzaja = null;
Metadata metadata;
AutoDetectParser parser;
try {
metadata = new Metadata();
is = new FileInputStream(putanja);
/**
* Maksimalan broj karaktera za upis u InputStream. -1 za MAX
*/
nosacSadrzaja = new BodyContentHandler(-1);
parser = new AutoDetectParser();
parser.parse(is, nosacSadrzaja, metadata, new ParseContext());
processMetaData(metadata);
sviMetapodaci(getMetaData());
//log.info(nosacSadrzaja.toString());
} catch (Exception e) {
e.printStackTrace();
} finally {
if (is != null)
IOUtils.closeQuietly(is);
}
return nosacSadrzaja.toString();
}
[/code]
Детаље TIKA библиотеке смо описали у чланку „Apache TIKA freamework” који је такође изашао у овом броју ЛиБРЕ! часописа, у рубрици „Интернет мреже и комуникације”. Детаље и упутство како покренути екстракцију су описани на адреси http://bit.ly/17CP0ew.
Пакетна структура пројекта
Пакетна структура пројеката писаних у Java програмском језику је идентична хијерархијској структури фасцикли фајл система у оперативном систему који користите. Свака фасцикла у Java-ином програму се назива „пакет”. Пакети (фасцикле) нам омогућавају да групишимо класе које по својој функцији и намени имају нешто заједничко, тако да смо, водећи се студијом случаја и дијаграмом описаних у прошлом броју, дошли до неког логичног закључка да би структура пројекта, прелиминарно, могла да изгледа као на слици.
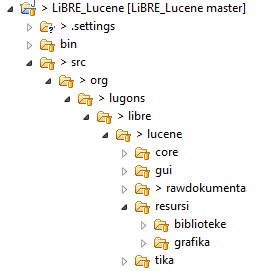
Прва два модула су у пакету „rawdokumenta”. Трећи имплементиран модул „Tika ekstrakcija” је у пакету који смо назвали „tika”, тако да ће изворни кôд апликације имати структуру коју ће бити лакше исправљати, одржавати, итд. Наравно да овим нисмо описали како се у Java програмирању конвенционално користе пакети, али то је тема за неки други чланак.
Иако смо до сада имплементирали три модула, они нису у директној вези са Lucene, али су ипак један од битнијих делова апликације и уопштено имплементације Lucene библиотеке. Парсирање, екстракција, издвајање података из разних структура података, било да су бинарног или неког другог формата, није наивно и треба да се обрати пажња на много детаља, почевши од проучавања и упознавања стандардизације типа документа који парсирамо, до семантичких детаља везаних за контекст самог текста.
У следећем броју ЛиБРЕ! часописа ћемо извршити имплементацију још два модула за које нам Lucene омогућава API (Application Programming Interface – API).