
Apache TIKA framework
Autor: Dejan Čugalj
Apache TIKA je skup alata otvorenog kôda za parsiranje (engl. parsing), ekstrakciju metapodataka (metadata extraction) i sadržaja (content extraction) iz datoteka različitih ekstenzija i formata, tako da bi se moglo reći da je TIKA, u stvari, programerski šablon (programming framework) za analizu sadržaja iz datoteka. Ceo projekat je pokrenut 22.3.2007. godine, a potprojekat Apache Lucene postaje 2008. godine, dok 2010. godine prelazi u samostalni projekat (Top-Level Project – TLP) Apache fondacije.
Apache TIKA ne pokušava da ponovo „izmisli točak”, već okuplja napisane biblioteke koje joj pomažu u ostvarivanju krajnjeg cilja. Primera radi, za analizu Microsoft Office dokumenata koristi Apache POI biblioteku (korisna adresa http://poi.apache.org/), za PDF datoteke koristi PDFBox (korisna adresa http://pdfbox.apache.org/) itd.
TIKA nudi generički API (Application Programming Interface), koji omogućava čitanje i ekstrakciju sadržaja iz skoro svih poznatih formata elektronskih dokumenata koji se koriste danas. Spisak svih podržanih formata možemo videti na adresi http://tika.apache.org/1.4/formats.html.

Moguća upotreba TIKA biblioteke ogleda se u sledećem slučaju. Pristižu neki podaci u PDF ili CSV formatu. Tada je potrebno da sadržaj koji je u spomenutim datotekama, bude sačuvan u bazu podataka ili da ga spremimo za indeksiranje pa potom pretragu. Prvo treba da izvučemo sadržaj iz tih datoteka, kao i njihove metapodatke, i to je mesto gde TIKA ulazi u igru. TIKA jednostavnim pozivom „org.apache.tika.parser.Parser” interfejsa sakriva svu kompleksnost koja se izvršava prilikom parsiranja dokumenata. Primeri iz stvarnog života upotrebe ovog alata su u NASA-inom data centru kao i u Institutu za rano otkrivanje raka (National Cancer Institute’s Early Detection Research Network – EDRN).
U članku koji je objavljen u ovom broju „Apache Lucene – Korak do Google-a”, predstavljamo implementaciju trećeg modula koji se naziva „TIKA ekstrakcija”. Implementacija ovog modula je zahtevala malo više programerskog kôda pa smo izdvojili samo deo koji je najbitniji za TIKA-u, a to je upravo spomenuti interfejs „org.apache.tika.parser.Parser”. Ovaj interfejs zaslužuje delić više prostora, pa ga predstavljamo sa malo više pažnje u ovom članku.
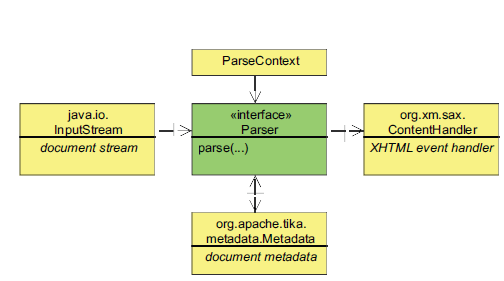
Parser interfejs („org.apache.tika.parser.Parser”)
packageorg.apache.tika.parser;
importjava.io.IOException;
importjava.io.InputStream;
importjava.util.Set;
importorg.apache.tika.exception.TikaException;
importorg.apache.tika.metadata.Metadata;
importorg.apache.tika.mime.MediaType;
importorg.apache.tika.parser.ParseContext;
importorg.xml.sax.ContentHandler;
importorg.xml.sax.SAXException;
/** Tika parser interface. */
publicinterfaceParser{
/** Returns the set of media types supported by this parser. */
Set<MediaType> getSupportedTypes(ParseContext context);
/** Parses a document stream into a XHTML SAX events and metadata. */
void parse(InputStream stream, ContentHandler handler, Metadata metadata, ParseContext context)throwsIOException, SAXException, TikaException;
}
Sama implementacija (uprošćeno) bi izgledala:
InputStream is = is =new
FileInputStream(putanja);
ContentHandler nosacSadrzaja =new BodyContentHandler();
Metadata metadata =new Metadata();
ParseContext parseContext =new ParseContext();
Parser parser =
new AutoDetectParser();
parser.parse(is, nosacSadrzaja , metadata, parseContext);
Ekstrakcija sadržaja (Content extraction)
InputStream (is)
Izvorni, ulazni podaci dokumenta – to su ulazni podaci dokumenta koji se parsira. Obično je to bajt (byte stream) ulazni tok podataka.
Content Handler (nosacSadrzaja)
Content Handler XHMTL SAX, rukovaoc događajima – Struktuiran sadržaj podataka ulaznog dokumenta se upisuje u ovaj rukovaoc događajima kao semantički XHTML dokument. Upotreba XHTML-a omogućava prikaz eksportovanog teksta u strukturu, kao što su: zaglavlja (headings), paragrafi (paragraphs) i hiperlinkovi (hyperlinks). Umesto serijalizacije XHTML izlaza u bajt tok podataka, on se prosleđuje SAX API-ju koji omogućava efikasno postprocesiranje ekstraktovanog teksta.
Metapodaci (metadata)
Metadata – metapodaci dokumenta pomažu TIKA biblioteci da bolje „razume” dokument koji se parsira. Kada kažemo razume, mislimo na format dokumenta koji joj je prosleđen. Takođe, možemo eksplicitno da prosledimo format datoteke za parsiranje, npr. za PDF dokumenta:
Parser parser =new PDFParser();
najčešći je slučaj da se TIKA koristi u delovima aplikacije koja je napisana za parsiranje više formata odjednom, te je implicitni model bolji:
Parser parser =new AutoDetectParser();
Takođe je korisno onda, kada ne želimo odmah da ekstraktujemo ceo sadržaj dokumenta (zahteva ipak neko vreme), već samo njegove metapodatke pa nakon pregleda istih, korisnik može da odabere iz kojih datoteka želi da ekstraktuje sadržaj.
ParseContext (parseContext)
PraseContext – proces parsiranja sadržaja je osnovni element TIKA biblioteke i ovaj argument se uzima kao „ozbiljan ”, onog momenta kada korisnik ima zahtev da se sadržaj ekstraktuje po nekim prethodno određenim kriterijumima. Primeri mogu da budu npr. XML parseri ili neki delovi HTML kôda određene stranice (hiperlinkovi, naslovi).
U ovom momentu bismo još samo želeli da napomenemo da prilikom preuzimanja JAR datoteke sa http://tika.apache.org/download.html, vi preuzimate i aplikaciju koja poseduje grafički interfejs, a ne samo API za programerski razvoj i sopstvenu implementaciju. Pokretanje grafičkog interfejsa se izvršava nakon komande:
java -jar tika-app.jar --gui

Nakon pokretanja je dovoljno samo prevući datoteku u prozor i čeka vas iznenađenje.
Da ukratko sumiramo, ovaj članak je samo pomoćni deo implementacije trećeg modula članka „Apache Lucene – Korak do Google-a”, mada je poseban. Nadamo se da smo uspeli makar malo da vam predstavimo šta sve može TIKA i koliko je korisna u ekstrakciji podataka.
Korisni linkovi: