
Apache TIKA framework
Аутор: Дејан Чугаљ
Apache TIKA је скуп алата отвореног кôда за парсирање (енгл. parsing), екстракцију метаподатака (metadata extraction) и садржаја (content extraction) из датотека различитих екстензија и формата, тако да би се могло рећи да је TIKA, у ствари, програмерски шаблон (programming framework) за анализу садржаја из датотека. Цео пројекат је покренут 22.3.2007. године, а потпројекат Apache Lucene постаје 2008. године, док 2010. године прелази у самостални пројекат (Top-Level Project – TLP) Apache фондације.
Apache TIKA не покушава да поново „измисли точак”, већ окупља написане библиотеке које јој помажу у остваривању крајњег циља. Примера ради, за анализу Microsoft Office докумената користи Apache POI библиотеку (корисна адреса http://poi.apache.org/), за PDF датотеке користи PDFBox (корисна адреса http://pdfbox.apache.org/) итд.
TIKA нуди генерички API (Application Programming Interface), који омогућава читање и екстракцију садржаја из скоро свих познатих формата електронских докумената који се користе данас. Списак свих подржаних формата можемо видети на адреси http://tika.apache.org/1.4/formats.html.

Могућа употреба TIKA библиотеке огледа се у следећем случају. Пристижу неки подаци у PDF или CSV формату. Тада је потребно да садржај који је у споменутим датотекама, буде сачуван у базу података или да га спремимо за индексирање па потом претрагу. Прво треба да извучемо садржај из тих датотека, као и њихове метаподатке, и то је место где TIKA улази у игру. TIKA једноставним позивом „org.apache.tika.parser.Parser” интерфејса сакрива сву комплексност која се извршава приликом парсирања докумената. Примери из стварног живота употребе овог алата су у NASA-ином data центру као и у Институту за рано откривање рака (National Cancer Institute’s Early Detection Research Network – EDRN).
У чланку који је објављен у овом броју „Apache Lucene – Корак до Google-a”, представљамо имплементацију трећег модула који се назива „TIKA екстракција”. Имплементација овог модула је захтевала мало више програмерског кôда па смо издвојили само део који је најбитнији за TIKA-у, а то је управо споменути интерфејс „org.apache.tika.parser.Parser”. Овај интерфејс заслужује делић више простора, па га представљамо са мало више пажње у овом чланку.
Парсер интерфејс („org.apache.tika.parser.Parser”)
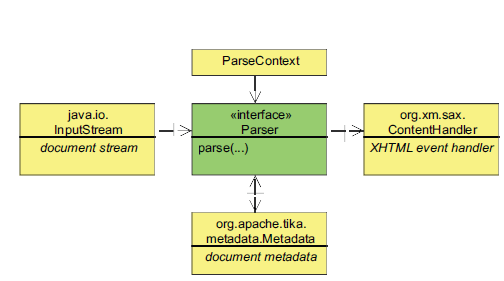
package org.apache.tika.parser;
import java.io.IOException;
import java.io.InputStream;
import java.util.Set;
import org.apache.tika.exception.TikaException;
import org.apache.tika.metadata.Metadata;
import org.apache.tika.mime.MediaType;
import org.apache.tika.parser.ParseContext;
import org.xml.sax.ContentHandler;
import org.xml.sax.SAXException;
/** Tika parser interface. */
public interface Parser {
/** Returns the set of media types supported by this parser. */
Set<MediaType> getSupportedTypes(ParseContext context);
/** Parses a document stream into a XHTML SAX events and metadata. */
void parse(InputStream stream, ContentHandler handler, Metadata metadata, ParseContext context) throws IOException, SAXException, TikaException;
}
Сама имплементација (упрошћено) би изгледала:
InputStream is = is = new
FileInputStream(putanja);
ContentHandler nosacSadrzaja = new BodyContentHandler();
Metadata metadata = new Metadata();
ParseContext parseContext = new ParseContext();
Parser parser =
new AutoDetectParser();
parser.parse(is, nosacSadrzaja , metadata, parseContext);
Екстракција садржаја (Content extraction)
InputStream (is)
Изворни, улазни подаци документа – то су улазни подаци документа који се парсира. Обично је то бајт (byte stream) улазни ток података.
Content Handler (nosacSadrzaja)
Content Handler XHMTL SAX, руковаоц догађајима – Структуиран садржај података улазног документа се уписује у овај руковаоц догађајима као семантички XHTML документ. Употреба XHTML-а омогућава приказ експортованог текста у структуру, као што су: заглавља (headings), параграфи (paragraphs) и хиперлинкови (hyperlinks). Уместо серијализације XHTML излаза у бајт ток података, он се прослеђује SAX API-ју који омогућава ефикасно постпроцесирање екстрактованог текста.
Метаподаци (metadata)
Metadata – метаподаци документа помажу TIKA библиотеци да боље „разуме” документ који се парсира. Када кажемо разуме, мислимо на формат документа који јој је прослеђен. Такође, можемо експлицитно да проследимо формат датотеке за парсирање, нпр. за PDF документа:
Parser parser = new PDFParser();
најчешћи је случај да се TIKA користи у деловима апликације која је написана за парсирање више формата одједном, те је имплицитни модел бољи:
Parser parser = new AutoDetectParser();
Такође је корисно онда, када не желимо одмах да екстрактујемо цео садржај документа (захтева ипак неко време), већ само његове метаподатке па након прегледа истих, корисник може да одабере из којих датотека жели да екстрактује садржај.
ParseContext (parseContext)
PraseContext – процес парсирања садржаја је основни елемент TIKA библиотеке и овај аргумент се узима као „озбиљан ”, оног момента када корисник има захтев да се садржај екстрактује по неким претходно одређеним критеријумима. Примери могу да буду нпр. XML парсери или неки делови HTML кôда одређене странице (хиперлинкови, наслови).
У овом моменту бисмо још само желели да напоменемо да приликом преузимања JAR датотеке са http://tika.apache.org/download.html, ви преузимате и апликацију која поседује графички интерфејс, а не само API за програмерски развој и сопствену имплементацију. Покретање графичког интерфејса се извршава након команде:
java -jar tika-app.jar --gui

Након покретања је довољно само превући датотеку у прозор и чека вас изненађење.
Да укратко сумирамо, овај чланак је само помоћни део имплементације трећег модула чланка „Apache Lucene – Корак до Google-a”, мада је посебан. Надамо се да смо успели макар мало да вам представимо шта све може TIKA и колико је корисна у екстракцији података.
Корисни линкови: