

Apache Lucene – корак до Google-а (5. део)
Аутор: Дејан Чугаљ
После паузе која је потрајала, враћамо се имплементацији модула који су нам неопходни за остварење крајњег циља који смо задали себи још у 12. броју ЛиБРЕ! часописа.
Последњи чланак о овој теми објављен је у 15. броју, и због тога ћемо се подсетити шта је све урађено до сада. У 12. броју смо представили неке упоредне податке људске потребе за претраживачима у информационим технологијама и укратко смо споменули Lucene библиотеку. Број 13. смо искористили за детаљније упознавање са истом, док смо у броју 14. потпуно ушли у причу и представили студију случаја предстојећег пројекта. У 15. броју ЛиБРЕ! часописа, тј. у четвртом наставку серије чланака „Lucene – корак до Google-а”, почињемо са имплементацијом пројектних модула Lucene пројекта. У том издању смо имплементирали прва два модула: „Проналазак свих PDF датотека” и „Tika екстракција”. Такође, овај изузетан Apache Tika framework нашао је своје место у засебном чланку и приближио нам своје могућности.
С обзиром на количину кôда који ће бити написан, одлучили смо се за GitHub јавни репозиторијум (Користан линк: https://github.com/libreoss/lucene-moduli) у који је постављен целокупан кôд, док оне најбитније делове објављујемо у часопису. Некако, када све саберемо и одузмемо, то је оно што би представило кратку рекапитулацију серијала „Lucene – корак до Google-а”.
Пети део серијала нам доноси наставак имплементације модула и то су: „Анализа докумената”, „Индексирање PDF датотека” и „Индекс (преглед Lucene структуре датотека)”. Ово је добар моменат да подсетимо да сви модули из студије случаја обојени зеленом бојом јесу тачније они делови где нам Lucene пружа своје услуге и довољно је само бити упознат са њеним API-јем (енгл. Application Programming Interface) да би се могла и користити. Управо тај API (http://bit.ly/SBcNKf) и документација доступни су на адреси: http://lucene.apache.org/core/4_8_0/index.html (верзија актуелна у току писања овог чланка је 4.8.0).
Пре него што почнемо, потребно је додати Lucene библиотеке у Eclipse IDE окружење, које су доступне за преузимање са званичног сајта на адреси: http://lucene.apache.org/core/. Додавање библиотека у пројекат Eclipse IDE окружења детаљно је објашњено на адреси: http://bit.ly/1qfFRpb
4. Анализа датотека

У првом делу серијала, ако сте пажљиво читали, дотакли смо се токенизације и шта би она укратко требало да представља (12. број ЛиБРЕ! часописа). Управо је ово део где она долази до значаја. Претраживачи не индексирају текст директно, већ се садржај, кандидат за индексирање, раставља на мање делове (Atomic part), који се називају token-и. Управо се овај процес одвија у овом модулу. Како се ово одвија имплицитно, око овог модула у овом моменту не морамо превише да бринемо, али ако бисмо се удубили у проблематику, видели бисмо да је од великог значаја и да је један од озбиљнијих проблема. Укратко, приликом овог процеса решавају се круцијална питања као што су: да ли је потребно обраћати пажњу на смисао речи (проблем синонима), да ли је потребно приликом претраживања обратити пажњу на семантичку страну природе речи као што су лаптоп и рачунар, да ли је потребно узимати у обзир инфинитив? Проблеми и питања се могу довести до филозофско-филолошког нивоа, тако да бисмо ову тему оставили за неке друге, филолошке науке. Оно што је битно за нас, јесте то да Lucene даје низ алата, са којима макар иоле можемо да се приближимо неким реалним резултатима. И коначно, долазимо до најбитнијег дела и сржи овог серијала, а то је „индексирање”.
5. Индексирање

До сада смо, можда и пречесто, спомињали ову фамозну реч „индексирање”, тако да ово заузима централни и најбитнији део целог серијала. Како би хтели да овај део буде респективно, колико је то могуће, приближан квалитету уложеног труда у развијању Lucene, овде стајемо и пример дајемо малим „школским примером” имплементације Lucene индексирања написаним у Java програмском језику. С обзиром да је ово централни (core) део серијала, респективно заслужује и место у њему, тако да ћемо га детаљно представити у следећем наставку.
[code]
import java.io.File;
import org.apache.lucene.analysis.Analyzer;
import org.apache.lucene.analysis.standard.StandardAnalyzer;
import org.apache.lucene.document.Document;
import org.apache.lucene.document.Field;
import org.apache.lucene.document.StringField;
import org.apache.lucene.index.IndexWriter;
import org.apache.lucene.index.IndexWriterConfig;
import org.apache.lucene.store.Directory;
import org.apache.lucene.store.FSDirectory;
import org.apache.lucene.util.Version;
/** * */
public class LuceneIndexExample {
public static void main(String args[]) throws Exception {
String text = "Ovo je tekst indeksiran sa Lucene";
String indexDir = System.getProperty("user.dir")
+ System.getProperty("file.separator") + "index";
System.out.println(indexDir);
Directory dir = FSDirectory.open(new File(indexDir));
Analyzer analyzer = new StandardAnalyzer(Version.LUCENE_48);
IndexWriterConfig iwc = new IndexWriterConfig(Version.LUCENE_48, analyzer);
IndexWriter writer = new IndexWriter(dir, iwc);
Document document = new Document();
Field pathField = new StringField("ime_polja", text, Field.Store.YES);
document.add(pathField);
writer.addDocument(document);
writer.close();
}
}
[/code]
6. Индекс (преглед Lucene структуре датотека)
 Основни и фундаменталан концепт Lucene јесу: индекс (index), документ (document), поље (field) и појам (term). Када бисмо то „склопили”, добили бисмо структуру да индекс садржи секвенце документа. Документ је секвенца поља, поље је именована секвенца појма, док је појам секвенца бајтова.
Основни и фундаменталан концепт Lucene јесу: индекс (index), документ (document), поље (field) и појам (term). Када бисмо то „склопили”, добили бисмо структуру да индекс садржи секвенце документа. Документ је секвенца поља, поље је именована секвенца појма, док је појам секвенца бајтова.
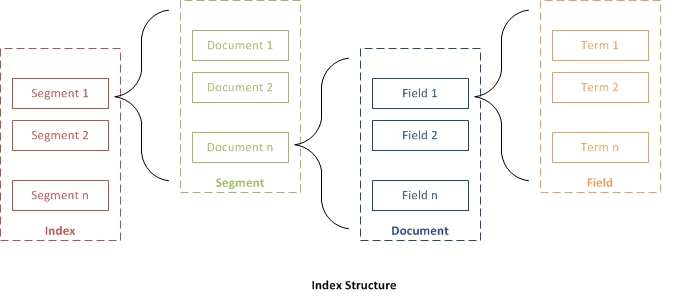
Углавном, цела магија се одвија под „Lucene хаубом” и, уколико бисмо желели да уђемо дубље у тематику, сигурно би нам понестало простора. Ово је сасвим довољно за стицање слике и сазнања да после индексирања, Lucene прави своју структуру фајлова која се после користи за претрагу.
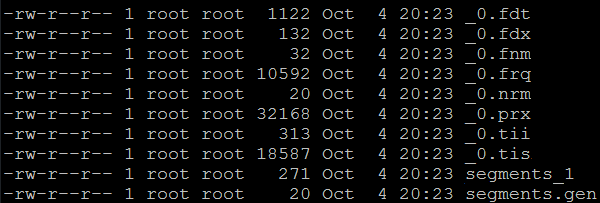
Видимо се у следећем броју са нашим „Lucene индексима”.
Корисни линкови:
-
Званични сајт: http://bit.ly/LdDxwN
-
Изворни кôд: http://bit.ly/1pIFmQo
-
Системски захтеви: http://bit.ly/1kN0bXP